
Introduction
Field mobile robots are extremely useful for operating in hazardous environments and performing urban search and rescue missions. To enhance mobility in unseen environments, most mobile robots are wirelessly operated. Although mobile robots have much potential in hazardous and hard-to-access environments, wireless connectivity has always been a limiting factor in the full-scale utilization of robots in these scenarios. As fully autonomous robots are reliable only in controlled environments, semi-autonomous control based on onboard sensing and computing remains the only viable means to reduce dependence on wireless connectivity. In the absence of connectivity with a human operator, the robot’s most critical computational task is obstacle identification. Since the robot may encounter many different types of obstacles, an alternative to identifying the obstacles themselves is to identify traversable areas in their field of sensing and then treat everything else as an obstacle.
Summary of Contributions
This work presents a new unsupervised algorithm for combining robotic sensing with monocular machine vision to detect the floor/road in any environment and suggest a semiautonomous control strategy for the Hybrid Mechanism Mobile Robot (HMMR). The proposed system uses low cost sensing modalities like ultrasonic sensors, monocular vision and inertial sensing which can be implemented in space constrained problems.
My work on this project focused on,
- Algorithm design , including image over segmentation, feature extraction, floor subset identification using ultrasonic sensor and inertial sensing and clustering and floor identification.
- Dataset building , data collection, data pre-processing, and ground truth labeling.
Proposed Obstacle Detection Method
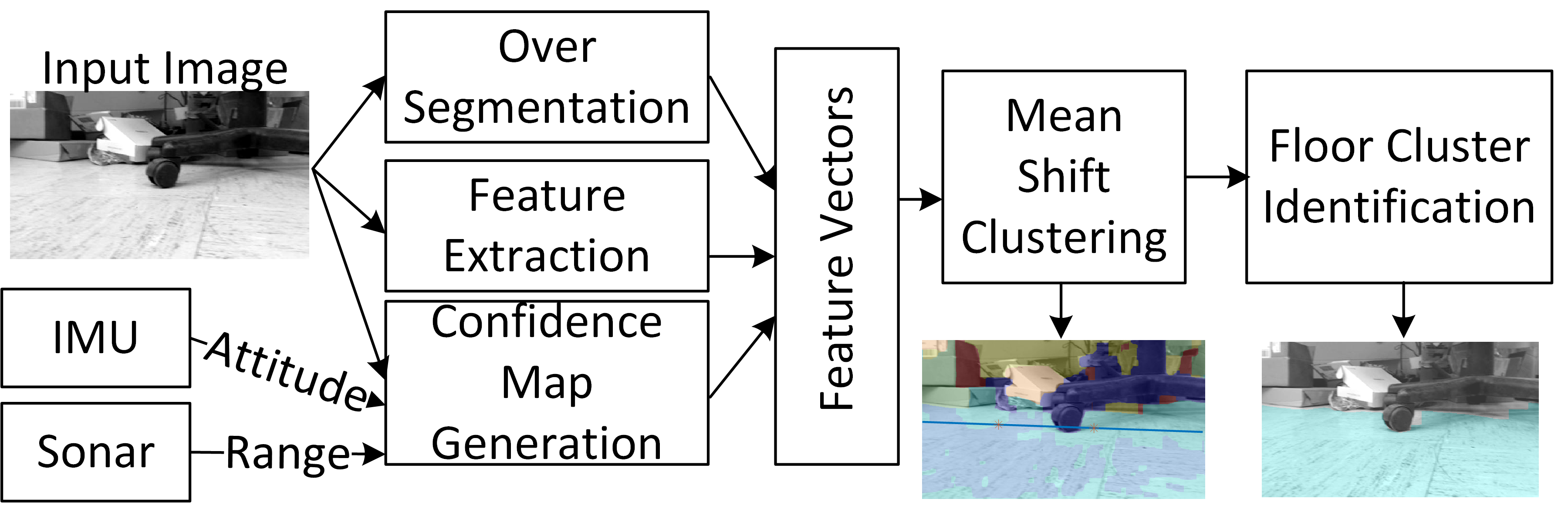
Fig. 1 Dataflow diagram of the proposed algorithm.
The most intuitive means of identifying area that is traversable by the robot is to identify the ground in the visual feed. The limited on-board computational capability of the HMMR requires simplicity in the segmentation process. The sole objective of the proposed method is to segment a given image \(I(x,y)\) by assigning labels \(L(x,y)\) to the pixels on the basis of regions/objects visible in the image and then classify the labels into ‘floor’ and ‘not-floor’ classes. The presented algorithm autonomously identifies the ground plane in a monocular video feed on the basis of multi-sensor cues without requiring any prior knowledge of the environment. The proposed algorithm can be divided into four major operations:
- Image Over-segmentation,
- Floor Subset Identification,
- Feature Extraction,
- Clustering and Floor Identification.
The proposed method first over-segments the input image to identify similar looking regions (superpixels) in the image in order to reduce computation time later in the process of the algorithm. Then, the algorithm combines ultrasonic sensor readings with the HMMR’s attitude information (from IMU) to identify the floor region subset. The method then uses the floor subset region along with results from the previous iterations to extract four-dimensional features, and assigns them to the corresponding super pixels. In this final stage, the proposed method clusters the super-pixels on the basis of feature and identifies clusters representing the floor. Figure 1 shows the overall dataflow diagram of the proposed method.

Fig. 2 Image Over-segmentation (A) Input Image (grayscale channel), (B) Colored watershed transform segments.
Image segmentation is essentially assigning labels to each pixel in an input image. Over-segmentation is used as a tool for dimensional reduction in image segmentation and thus drastically reduces computational requirements, as shown in Fig. 2.
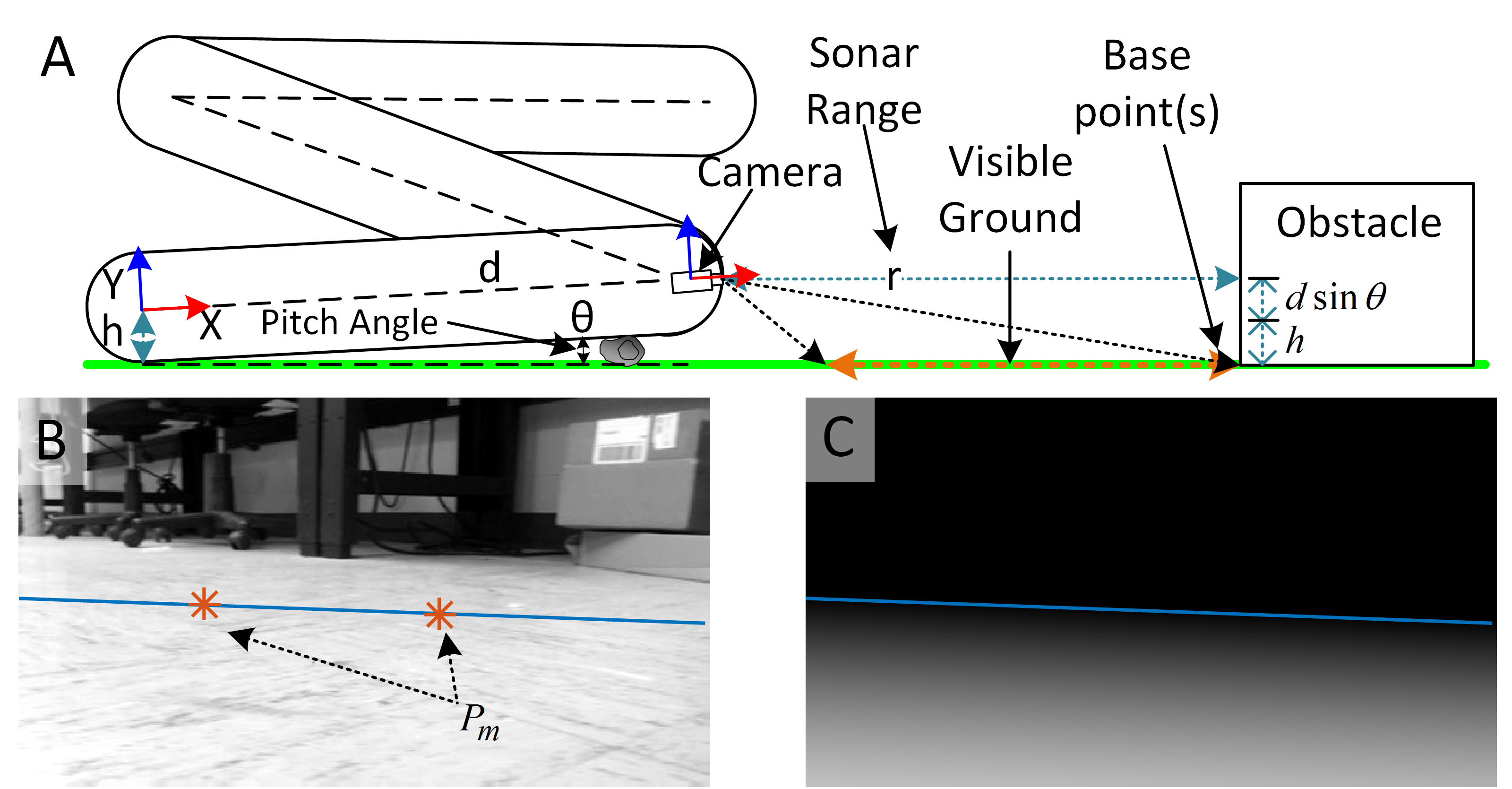
Fig. 3 Floor subset Identification: (A) Perception schematics, (B) Base point markers, (C) Floor confidence map.
Separating the floor from the background in images requires prior knowledge of the floor in the image domain. The HMMR uses IMU/AHRS data along with ultrasonic sonar sensor measurement to detect the floor subset in an image, as shown in Fig. 3.
Fig. 4 Feature extraction: (A) Superpixels, (B) Intensity channel, and (C) b* color channel.

Fig. 5 Texture feature: (A) Input image (grayscale channel), (B) GLCM texture descriptor, and (C) Pixelated texture descriptor on superpixels.
Fig. 6 Floor boundary cue: (A) Input image (grayscale channel), (B) Horizontal edges, and (C) Cumulated edge map.
Different kinds of features were extracted from the original images to provide as cues for traversable area detections as shown in Fig. 4-6.

Fig. 7 Floor Detection: (A) Superpixels, (B) Image segments, and (C) Final floor segment.
The processed superpixels were then congregated into image segments by using mean shift clustering with a bandwidth of 0.25 as shown in Fig. 7. The image segments falling 50% or more below the line connecting base markers were labelled as floor, shown in blue.
Fig. 8 Floor detection results in a video image sequence.
To validate the proposed method, a 13-second video filmed at 30 FPS was recorded in the lab, resulting in 408 frames, and used as the test dataset. The Tanimoto Index (TI) is used to measure algorithm performance quantitatively. Performance analysis shows that 89.95% of the frames were over 0.9.

Fig. 9 Performance analysis of floor segmentation.
Related Publication:
- [C1] Ren, H., Kumar, A., Ben-Tzvi, P., "Obstacle Identification for Vision Assisted Control Architecture of a Hybrid Mechanism Mobile Robot", Proceedings of the ASME 2017 Dynamic Systems and Control Conf. (DSCC 2017), Tysons Corner, VA,Oct 11-13, 2017.